There’s a hard truth about AI agents that many people still avoid.
If you are not measuring how your agent reasons, plans, and acts, then you are not really in control. You are just guessing.
For years, AI progress was measured by the size of the model, the creativity of the prompt, and the quality of the output. Everyone hoped for better performance. Few checked for reliability.
That era is ending.
The future belongs to teams who treat evaluation as a core function of development, not an afterthought.
Why Evaluation Matters More Than Ever
AI agents are fundamentally different from traditional software.
They do not follow static rules. They adapt, explore, and often operate with a degree of autonomy. That flexibility is powerful — but it also introduces risk.
Without structured evaluation, agents can hallucinate information. They can lose track of context. They can fail when task requirements shift or when they encounter unexpected inputs.
And when that happens silently, the consequences stack up. Customers are misinformed. Operations break. Trust erodes.
If you are not actively testing your agents under stress, you are not ready to scale them in production.
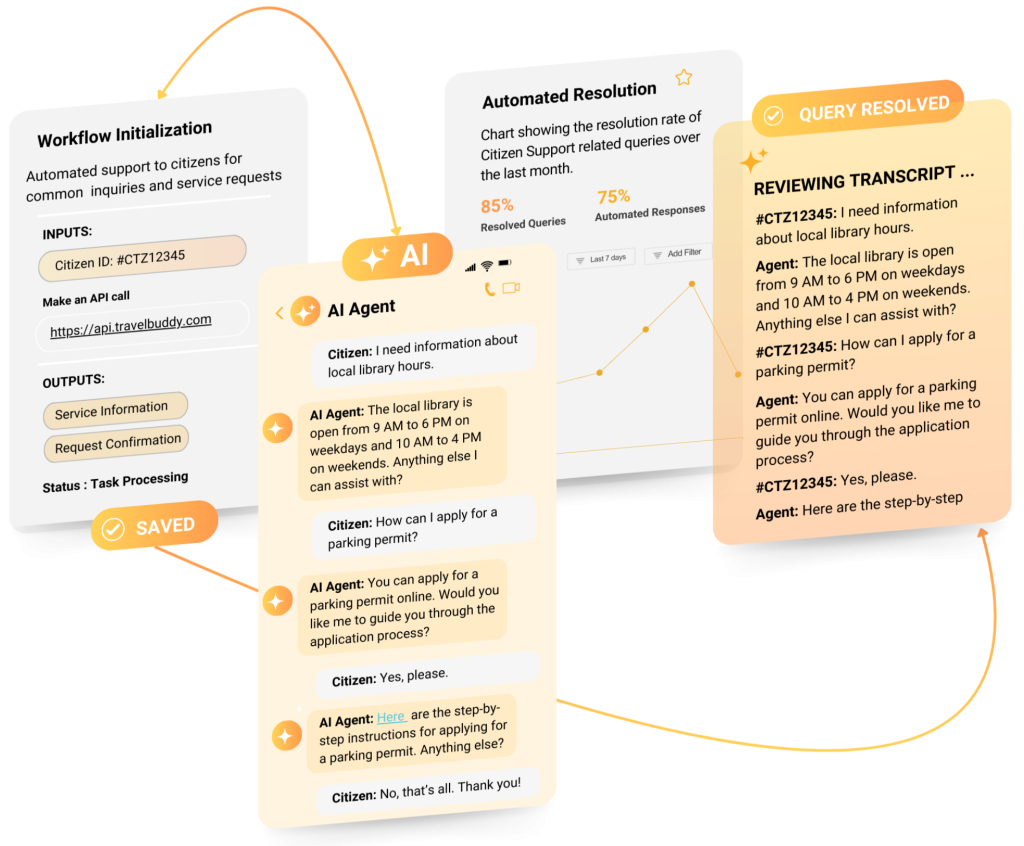
What Evaluation Looks Like at EasyBee AI
At EasyBee AI, we build evaluation directly into how we design, ship, and improve our agents.
Every agent built on our Hex architecture is tested across three critical functions:
- How it reasons
- How it remembers
- How it responds to evolving tasks and incomplete data
These evaluations are not run once. They are continuous.
We simulate real-world edge cases. We remove tools mid-process. We break context intentionally. Then we measure how the agent responds.
Because real-world environments are rarely clean. And if an agent cannot operate under pressure, it should not be in production.
Performance Beyond the Demo
Right now, most leading agents can handle three to five step tasks under ideal conditions.
But as soon as inputs become messy, or a key tool is missing, failure rates spike.
These are the blind spots most teams do not find until it is too late.
Evaluation is what separates a polished demo from a dependable product.
The Future of Trustworthy AI
As agents become more autonomous and embedded in core workflows, evaluation will no longer be optional.
It will be expected by customers. It will be required by regulators. It will be the baseline for trust.
Teams that build with evaluation at the center today will have a lasting advantage tomorrow.
Better demos are easy.
Better decisions are hard.
Which one are you building for?